点赞计数器的一些思考
前置知识:
Mysql 5.6、RabbitMq 3.11.8、Redis 7.0.8 底层数据结构
最近在实现一个点赞接口,简单的来说就是用户对一个视频点赞后,会产生点赞信息,并且将视频点赞计数器加1,整体设计思路以及设计过程如下:
基于Mysql的计数器
首先我们要设计两张Mysql表
-
点赞关系表
like_record:字段名称 类型 意义 id bigint 点赞用户ID user_id bigint 用户ID video_id bigint 视频ID is_del bool 是否删除 软删除 update_at timestamp 更新时间 -
点赞计数表
video_counter字段名称 类型 意义 video_id bigint 视频ID like_count bigint 喜欢计数器 forward_count bigint 转发计数器 comment_count bigint 评论计数器
具体业务逻辑是
- 点赞的时候,插入
like_record并且更新video_counter计数器。 - 取消点赞的时候,
- 如果
like_record存在相关记录,那么直接更新is_del = 1,并且更新video_counter计数器 - 如果不存在相关记录,那么直接在
like_record插入相关数据,并且更新video_counter计数器
- 如果
可以看到进行一次点赞请求,我们需要两次操作数据库操作。因此耗时比较多。
优缺点分析
- 点赞属于用户无意识行为,频率较大,所以在高并发场景下,仅仅通过数据库不可能扛得住的
video_counter表在需要拓展其他计数器的时候,可能需要修改表结构,扩展能力不足
基于Redis计数器
在单独用Mysql来实现的讨论中,发现对于点赞技术的查询、修改都是在数据库中进行,这就意味着要和磁盘打交道了,对于CPU来说这是一个灾难。需要注意的是不同于其他地方的缓存策略,计数器的修改和查询必须在缓存中操作,也就是计数器数据在缓存中操作,而非DB层
Version 1 (Fast)
为了解决点赞操作缓慢这个问题,在version 1中,考虑将视频的点赞信息放到缓存中,同时点赞的计数操作可以直接在内存中进行+1 or -1操作,也就是在缓存中做一个计数器。
那可能会有同学问了,
- Cache中的数据是易失的,突然宕机了怎么办?在这里
Redis的持久化机制就派上用场了,可以手动开启RDB和AOF两种持久化机制。 - DB中记录点赞关系表,Cache中记录点赞总数,如果不一致怎么办?这个稍后再讨论,毕竟这是小概率问题。
好了解决了缓存实现中的一些疑问点,现在着手设计叭!
首先要在Redis中为每个视频设置一个计数器,我们将KEY设计为
counter:video_id:like:代表视频点赞数,其中video_id需要替换成具体视频IDcounter:video_id:comment:代表视频评论数,其中video_id需要替换成具体视频IDcounter:video_id:forward:代表视频转发数,其中video_id需要替换成具体视频ID
VALUE设计成普通的INT编码的String对象,具体操作是这样的:
set counter:1:like 1 #设置计数器
incr counter:1:like #点赞计数器加一
decr counter:1:like #点赞计数器减一
到这,来捋一下具体一个操作逻辑:
- 点赞请求

- 查询点赞数数:

Version 2 (Asyn)
对于Version 1,我们发现在点赞视频的时候,还是会操作数据库,而且在数据库和缓存的数据,不太需要强一致性,因此可考虑做异步处理,也就是文首提到的RabbitMQ
系统只需要更新Redis计数器中的值,然后将入库操作发送到MQ中,起到了异步请求和削峰填谷的作用。又一个进程来充当消费者对

关于缓存和数据库的数据不一致情况,可以在用户量的时候设置一个定时任务做同步处理:

Version 3 (Smaller Space)
简单分析
以上我们简单实现了基于Redis和MQ的点赞计数器,当时内存容量通常来说是远远小于磁盘的。如何物尽其用,降低成本呢?接下来我们着重解决内存占用问题。
如果采用Version 1中方案,我们为每个视频设置4个计数器,需要个键值对,在Redis中,K-V对都是由String对象类型表示,Redis对象结构在Redis中表示如下: Redis底层实现
typedef struct redisObject{
//类型
unsigned type; //4bit
//编码
unsigned encoding; //4bit
//对象空转时长:记录了对象最后一次命令程序访问的时间
//可以配合回收算法进行allkeys-lru volatile-lru使用
unsigned lru; //24bit
//指向底层数据结构的指针
void *ptr; //64位操作系统占用8B
//引用计数
int refcount; //4B
//....
}robj;
-
计数器的Value值的是整数值(long类型),所以其默认底层编码是
REDIS_ENCODING_INT,因此具体存储结构如下:也就是ptr指针直接被换成了我们要存储的整型值因此对于计数器的值存储,共占用 (4bit+4bit+24bit)/8(type lru encode) + 4B(refcount) + 8B(ptr) = 16B
-
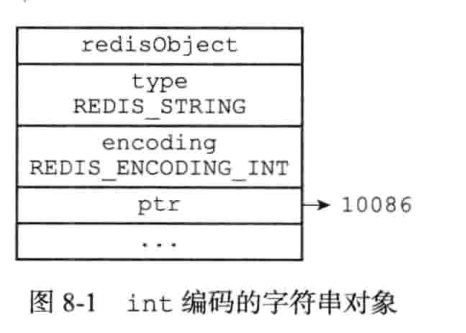
计数器的Key值是字符串,且不超过32字节,所以其默认底层编码是
REDIS_ENCODING_RAW,因此具体存储结构如下:也就是ptr指针直接被换成了我们要存储的SDS结构体typedef char *sds; struct sdshdr { unsigned int len; //4B unsigned int free; //4B char buf[]; //字符串长度 + 1 };因此具体存储结构为:
对于计数器的键counter:1:like存储,共占用 (4bit(type)+4bit(lru)+24bit(encoding))/8 + 4B(refcount) + 8B(ptr) + (4B(len) + 4B(free) + (26B)(SDS)= 50B
因此set counter:99999999999:like 1共占用 50B + 16B = 66B,如果为单个视频设置个计数器,那么一个视频的计数器占用了4 * 66 = 264B, 假设64位系统为Redis分配4GB内存,可以存储 4 * 1024 * 1024 / 264 = 15887个视频计数器。对于视频来说远不止这个数,可以说占用是非常大的。因此需要想办法使用一些办法实现这个计数器:
优化:这里采用一种方法:采用Hash对象来存储我们的值,Hash对象的编码方式有ziplist 和 hashtable,其中ziplist就是为了节约空间而设计的。
底层结构初识
先来分析一下ziplist编码下的hash对象基本结构:
Hash使用 ziplist 编码的要求是
- 所有键值对的长度都小于64B
- Hash保存的键值对的数量小于512;不能满足这两个条件使用
hashtable编码


- zlbytes 压缩列表占用字节数 占用 4B
- zltail 压缩列表末尾距首部多少字节 占用 4B
- zllen 压缩列表包含的节点数目 占用2B
- zlend 标记末尾 占用 1B
再来分析一下 Zentry

- previous_entry_length 标记前一个节点的长度, 为 1B
- encoding 记录节点的编码格式, 为 1B
- content 记录内容,因为计数存储的是
int64_t类型, 所以占用8B, 或者是int16_t类型,占用2B
优化思路
当我们要为 video_id 为 counter:like:9999999999 设置计数为 countNum的时候
- 首先提取是存在Redis中的Hash对象的Key,为将
key = video_id & 0x01FF - 然后提取出Hash键值对Map中的Counter Key为
counterkey = video_id >> 9 - 执行
hset key counterkey countNum
注:上面的 key 计算过程就是取最低9位,因为为了保证Hash由ziplist编码,所以一个Hash Key不能超过hash-max- ziplist-entries配置。该配置默认是 512, 也就是存储 512个键值对情况下,采用ziplist编码,该值也可以在配置文件配置。
性能对比
注:分析 set counter:like:99999999999 9999999999 总共占用多少内存?
由于一个Hash数据类型 最多保存512个键值对才能满足ziplist编码,所以下面以512个counter分析:
-
HashKey是采用SDS存储的字符串对象:
8B(object ptr) + 4B(lru and encoding) + 4B (ref count) + 4B(sds_free) + 4B(sds_len) + 4B(buf) = 16B + 9B + 21B = 47B -
Counter Key由Entry结构存储,占用:
1B(previous_entry_length) + 1B(encoding) + 2B(content int_16) = 4B -
Counter Value 由Entry结构存储,占用:
1B(previous_entry_length) + 1B(encoding) + 8B(content int_64) = 4B = 10B
因此一个键值对占用 14B, 512个键值对占用 7168B, 加上压缩列表的其他占用共 7168B + 11B(zllen + zlbytes + ztail + zend) = 7179B 因此,共使用47B + 7179B = 7226B保存了512个Counter ; 则单个视频设置4个Counter的情况下,4GB内存可保存的视频数为:4 * 1024 * 1024 / 7226 * 512 / 4 = 74,297, 相对于原始存储,存储效率提升了接近74297 / 15887 = 4.6倍!
总结
本篇文章首先讨论了基于Mysql的点赞计数器实现所带来的弊端,随后提出了基于Redis实现的点赞计数器,又在此基础上从以下两个方面进行深入探究:
- 性能方面,将计数逻辑在Redis中使用
lua脚本实现,而入库操作使用RabbitMQ进行异步处理。其中带来的缓存一致性问题用定时器解决。经过测试,该接口单机环境下TPS可达1800+! - 空间方面,通过分析使用基于
SDS以及INT编码下的String对象类型记录每个Counter,与使用基于ziplist编码下的Hash对象进行对比,通过简单计算得出4GB内存条件下两者的内存占用,最终得出后者的存储效率提升了近倍!
可以看到,点赞接口作为一个项目中的小功能,无论是架构上还是实现上,无论是从性能上或者空间占用上,其实都有着许多要值得深究的地方,这不仅会带来用户体验的提升,更是对生产成本的巨大节约。当然这需要对技术深入了解和探索,这一点笔者还在努力!如果纰漏,还请指正!
参考资料
- https://kernelmaker.github.io/Redis-StringMem
- Redis设计与实现 黄健宏
- Redis 5 设计与源码分析
- 来聊聊Redis底层数据结构叭



