
IO多路复用机制
什么是流?
- 流是可以进行I/O操作的对象
- 文件、管道、套接字
- 流的入口 就是 fd
什么是阻塞和非阻塞?
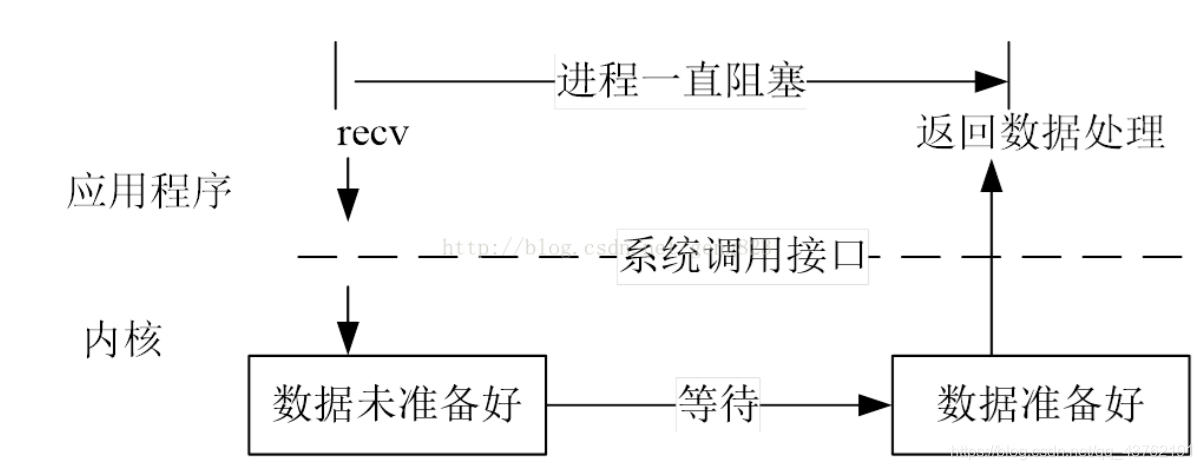
阻塞是发生在I/O调用阶段,当某个流连接进来,那该进程是否需要阻塞的等待这个流的状态发生变化,或者不阻塞等待而去每隔一段时间去查看socket和IO管道的数据是否到达,那么这就叫阻塞与非阻塞。
处理方法
阻塞+多线程
同一时刻,同一个线程只能监听同一个流。
创建多个线程去监听多个流,可能会造成资源的浪费。
while(true){
new Thread(()->{
bind(fd, thread);
})
}
非阻塞+轮询
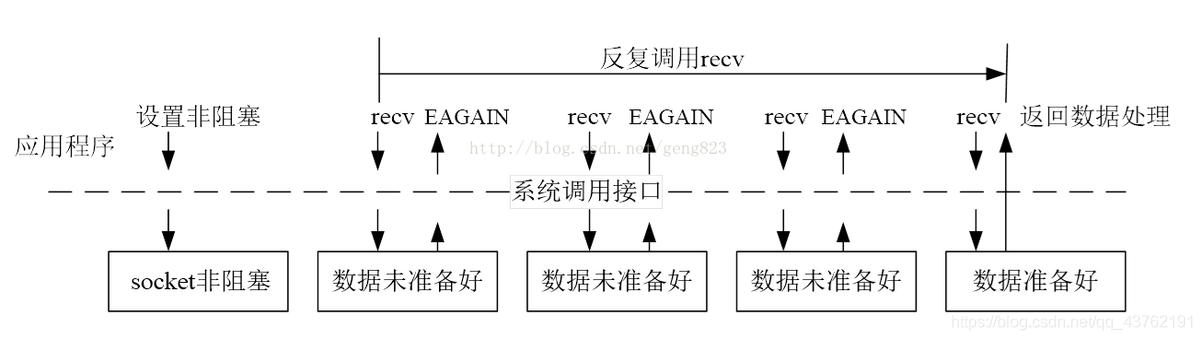
处理器去轮询查询各个流,然后查看是否有数据。可能造成处理器的调用过高。
while(true){
for i in 流[]:
if i has 数据:
//处理
}
select
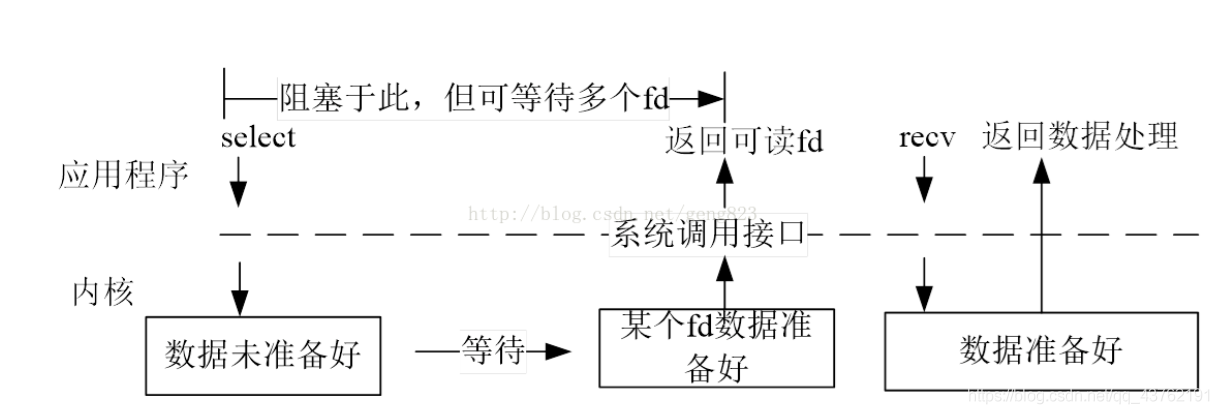
通过select函数去监听多个流,当流状态发生变化的时候,就会告诉处理机,但是不会指明哪个流状态发生了变化。
缺点
- 最大的缺陷是单个进程打开的FD是有一定限制的,默认是1024(32位),2048(64位)
- 对socket进行扫描时是线性扫描,即采用轮询方式,效率比较低。
- 需要维护一个用来存在大量fd的数据结构,用户态内核态复制开销大。
while(true){
select(流[]); //阻塞,CPU执行其他事务
for i in 流[]{ //遍历全部流
if i has 数据
//处理数据
}
}
epoll
和select一样都是都是IO多路复用技术,但是区别在于它只关心活跃的数据,无需遍历所有的文件描述集合。
它能够处理大量的连接请求。
cat /proc/sys/fs/file-max
while(1){
可处理的流[] = epoll_wait();
for i in 可处理的流[]:
//处理流。
}
epoll API
1. epoll_create(int size)
创建一个epoll句柄,参数size用于告诉内核监听的文件描述符个数,跟内存大小有关。 返回epoll文件描述符。这个句柄指向了一份文件描述符集合。
epoll在Linux内核中构建了一个文件系统,该文件系统采用红黑树来构建,红黑树在增加和删除上面的效率极高,因此是epoll高效的原因之一。有兴趣可以百度红黑树了解,但在这里你只需知道其算法效率超高即可。
2.epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)

传入一个event,将其加载到epfd,用户态给某个fd设置了事件,当其绑定的fd发生了events事件中的几个触发条件的时候,就会告诉上层,内核态就会告知用户态。
3.epoll_wait()

struct epoll_event my_event[1000]; //创建event数组用于接收被激活的events
int epoll_cnt = epoll_wait(eptd, my_event, 1000, -1); //会将被激活的events放入my_event中并返回数量;
4.编程框架

5.水平触发和边缘触发
(LT)水平触发就是当epoll_wait()抛出events集合时,如果用户态不解决,那么下一次epoll_wait就会返回
(ET)边缘触发就是通知用户态一次,不管会不会触发,下一次epoll_wait不会返回。
6.优点
- 通过每个fd上的
callback()函数来实现的,只有活跃的socket才会主动调用callback(),在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题 epoll通过内核和用户空间共享一块内存来实现。
参考资料
- https://developer.huawei.com/consumer/cn/forum/topic/0202522635419770580
- https://mp.weixin.qq.com/s?__biz=Mzk0MjE3NDE0Ng%3D%3D&chksm=c2c5967ff5b21f69030636334f6a5a7dc52c0f4de9b668f7bac15b2c1a2660ae533dd9878c7c&idx=1&mid=2247494866&scene=21&sn=0ebeb60dbc1fd7f9473943df7ce5fd95#wechat_redirect



